
Integrating Whisper Transcription with Transformer and CNN Models for Indonesian Abusive Speech Detection
Keywords:
Abusive Word Detection, Social Media, IndoBERT, Convolutional Neural Network (CNN), Text ClassificationAbstract
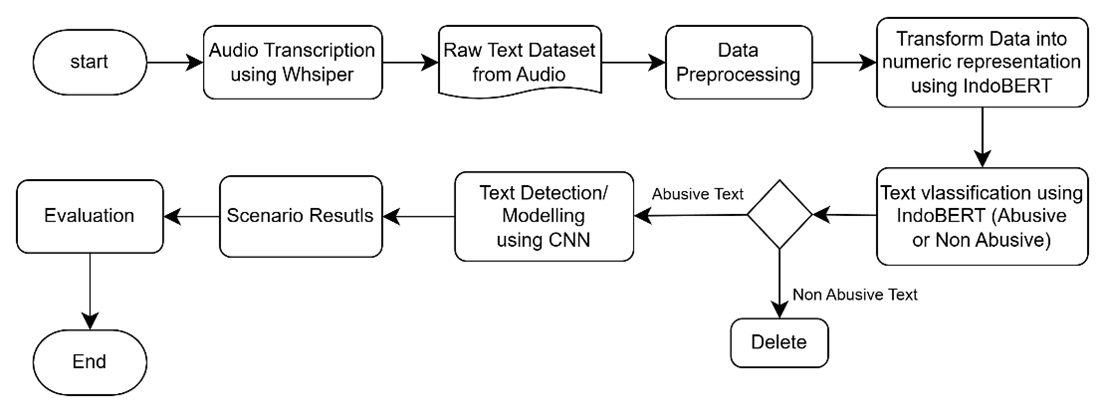
The growing popularity of audio social media in Indonesia has fueled the spread of profanity and hate speech, even though there are no regulations specifically covering its use. In this work, we propose an audio-based coarse word detection model by combining one Whisper model for transcription and another IndoBERT in a sentence context classifier to decode it along with a Convolutional Neural Network (CNN) for fine-grained coarse word prediction. The development of IDSS was based on a Knowledge Discovery in Database (KDD) process, consisting of the data selection, preprocessing, transformation, data mining and evaluation phases. The recovered dataset will be pre-processed through cleaning, tokenizing and stemming accordingly prior to labeling. To evaluate the data sharing strategies we used three proportions of shared information (80:20, 70:30 and 60:40) with 5-fold cross-validation. It was found that scenario 1 having data sharing ratio of 80:20 gave highest performance with 100% training accuracy, 98.71% validation accuracy and 99.57% test accuracy. The fusion of IndoBERT and CNN seems to be effective in finding broad sentences and certain words including rudeness. The proposed system would be a first line of defense in reducing the dissemination of hateful language content on auditory social media.
References
[1] A. P. Nugraha, A. Kurnia, P. Irawan, P. Putra, A. Rahman, and D. Dikrurahman, “The Impact of Social Media on Social Interaction and Self-Identity in Indonesian Society,” Journal of Social Research, no. 9, 2024, doi: 10.55324/josr.v3i9.2254.
[2] N. Aminudin, N. Hidayat, D. Feriyanto, D. Septasari, and I. Awaliyani, “Digital Landscape and Behavior in Indonesia 2024: A National Survey Analysis of Internet Penetration, Cybersecurity Risks, and User Segmentation Using K-Means Clustering and Logistic Regression,” Jurnal Teknik Informatika (Jutif), vol. 6, no. 5, pp. 3336–3351, Oct. 2025, doi: 10.52436/1.jutif.2025.6.5.5117.
[3] S. Dharmawan, ) Viny, C. Mawardi, ) Novario, and J. Perdana, “Klasifikasi Ujaran Kebencian Menggunakan Metode FeedForward Neural Network (IndoBERT),” Jurnal Ilmu Komputer dan Sistem Informasi, vol. 11, no. 1, 2023, doi: 10.24912/jiksi.v11i1.24066.
[4] F. Ihsan, I. Iskandar, N. S. Harahap, and S. Agustian, “Decision tree algorithm for multi-label hate speech and abusive language detection in Indonesian Twitter,” Jurnal Teknologi dan Sistem Komputer, vol. 9, no. 4, pp. 199–204, Oct. 2021, doi: 10.14710/jtsiskom.2021.13907.
[5] M. F. Majid and A. Solichin, “Aplikasi Pendeteksi Kalimat Kasar Bahasa Indonesia Pada File Audio Menggunakan Jaccard Similarity Dan N-Gram,” Jurnal TICOM: Technology of Information and Communication, vol. 12, no. 1, 2023, doi: 10.70309/ticom.v12i1.100.
[6] M. F. Salim and T. R. Iman, “Penggunaan Bahasa Kasar oleh Remaja Laki-laki BTN Karang Dima Indah Sumbawa dalam Pergaulannya,” KAGANGA KOMUNIKA (Journal of Communication Science), vol. 4, no. 2, 2022, doi: 10.36761/kagangakomunika.v4i2.2054.
[7] N. A. Shafira and Irhamah, “Klasifikasi Sentimen Ulasan Film Indonesia dengan Konversi Speech-to-Text (STT) Menggunakan Metode Convolutional Neural Network (CNN),” Jurnal Sains dan Seni ITS, vol. 9, no. 1, 2020, doi: 10.12962/j23373520.v9i1.51825.
[8] Nurjoko and A. Rahardi, “Model Indo-BERT untuk Identifikasi Sentimen Kekerasan Verbal di Twitter,” IJCCS, vol. 18, pp. 583–593, 2024, doi: 10.5281/zenodo.12788184.
[9] A. S. Simbolon, N. I. Pangaribuan, and N. M. Aruan, “Sentiment Analysis for E-learning Application using Support Vector Machine and Convolutional Neural Network,” SEMINASTIKA, vol. 3, no. 1, pp. 16–25, Nov. 2021, doi: 10.47002/seminastika.v3i1.236.
[10] D. A. N. Taradhita and I. K. G. D. Putra, “Hate Speech Classification in Indonesian Language Tweets by Using Convolutional Neural Network,” Journal of ICT Research and Applications, vol. 14, no. 3, pp. 225–239, 2021, doi: 10.5614/itbj.ict.res.appl.2021.14.3.2.
[11] F. Alghifari and D. Juardi, “Penerapan Data Mining Pada Penjualan Makanan Dan Minuman Menggunakan Metode Algoritma Naïve Bayes,” Jurnal Ilmiah Informatika (JIF), vol. 9, no. 2, 2021, doi: 10.33884/jif.v9i02.3755.
[12] I. K. J. Arta, G. Indrawan, ) Gede, and G. R. Dantes, “Data Mining Rekomendasi Calon Mahasiswa Berprestasi di STMIK Denpasar Menggunakan Metode Technique for Others Reference by Similarity to Ideal Solution,” Jurnal Ilmu Komputer Indonesia (JIKI), vol. 4, no. 1, 2019, doi: 10.23887/jik.v4i1.2765.
[13] F. Anistya and E. B. Setiawan, “Hate Speech Detection on Twitter in Indonesia with Feature Expansion Using GloVe,” Jurnal RESTI, vol. 5, no. 6, pp. 1044–1051, Dec. 2021, doi: 10.29207/resti.v5i6.3521.
[14] H. A. Prathama and I. P. G. H. Suputra, “Evaluasi UI pada Prototype Aplikasi ‘WeCare’ Menggunakan Metode SUS (System Usability Scale),” JNATIA, vol. 2, no. 1, 2023, doi: 10.24843/JNATIA.2023.v02.i01.p15.
[15] Rianto, A. B. Mutiara, E. P. Wibowo, and P. I. Santosa, “Improving the Accuracy of Text Classification Using Stemming Method, a Case of Non-formal Indonesian Conversation,” J Big Data, vol. 8, 2021, doi: 10.1186/s40537-021-00413-1.
[16] M. Das, S. Kamalanathan, and P. Alphonse, “A Comparative Study on TF-IDF Feature Weighting Method and its Analysis Using Unstructured Dataset,” Computational Linguistics and Intelligent Systems, 2023, doi: 10.48550/arXiv.2308.04037.
[17] A. C. Saputra, A. S. Saragih, and D. Ronaldo, “Prediksi Emosi dalam Teks Bahasa Indonesia Menggunakan Model Indobert,” Jurnal Teknologi Indormasi: Jurnal Keilmuan dan Aplikasi Bidang Teknik Informatika, vol. 19, 2025, doi: 10.47111/jti.v19i1.17617.
[18] N. Istiqomah and F. Novika, “Perbandingan Kinerja Model NER IndoBERT dan IndoLEM dalam Ekstraksi Informasi Kesehatan Pascabencana dari Berita Daring di Indonesia,” JOURNAL OF COMPUTER SCIENCE AND INFORMATICS ENGINEERING, vol. 04, no. 3, pp. 158–174, 2025, doi: 10.55537/cosie.v4i3.1173.
[19] N. M. Andini, Y. Findawati, I. R. I. Astutik, and A. Eviyanti, “Implementasi Convolutional Neural Network (CNN) Untuk Mendeteksi Ujaran Kebencian Dan Emosi Di Twitter,” SMATIKA JURNAL, vol. 14, no. 02, pp. 314–325, 2024, doi: 10.32664/smatika.v14i02.1346.
[20] A. Elouali, Z. Elberrichi, and N. Elouali, “Hate Speech Detection on Multilingual Twitter Using Convolutional Neural Networks,” Revue d’Intelligence Artificielle, vol. 34, no. 1, pp. 81–88, 2020, doi: 10.18280/ria.340111.
Downloads
Published
Issue
Section
License
Copyright (c) 2025 Ainandita Riwipapusa, Wiyli Yustanti, Cendra Devayana Putra, Bartolomeus Priya Perkasa Utama Widada (Author)

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.

